硬件对齐+原生训练!DeepSeek NSA打造高效稀疏Attention
一、研究背景与动机在自然语言处理领域,长上下文建模对下一代大语言模型至关重要,其应用场景广
一、研究背景与动机
在自然语言处理领域,长上下文建模对下一代大语言模型至关重要,其应用场景广泛,如深度推理、代码生成、多轮对话等。然而,标准注意力机制计算复杂度高,当处理长序列时,计算成本剧增,成为模型发展的瓶颈。以解码64k长度上下文为例,softmax注意力计算的延迟占总延迟的70 - 80%,这凸显了寻求高效注意力机制的紧迫性。
为提升效率,利用softmax注意力的固有稀疏性是一种可行途径,即选择性计算关键查询 - 键对,在保持性能的同时降低计算开销。现有方法虽各有探索,但在实际应用中存在诸多局限:
推理效率假象:许多稀疏注意力方法在推理时未能实现预期的加速效果。一方面,部分方法存在阶段受限的稀疏性,如H2O在解码阶段应用稀疏性,但预填充阶段计算量大;MInference则只关注预填充阶段稀疏性,导致至少一个阶段计算成本与全注意力相当,无法在不同推理负载下有效加速。另一方面,一些方法与先进注意力架构不兼容,如Quest在基于GQA的模型中,虽能减少计算操作,但KV缓存内存访问量仍较高,无法充分利用先进架构的优势。可训练稀疏性的误区:仅在推理阶段应用稀疏性会导致模型性能下降,且现有稀疏注意力方法大多未有效解决训练阶段的计算挑战。例如,基于聚类的方法(如ClusterKV)存在动态聚类计算开销大、算子优化困难、实现受限等问题;一些方法的离散操作(如MagicPIG中的SimHash选择)使计算图不连续,阻碍梯度传播;HashAttention等方法的非连续内存访问模式,无法有效利用快速注意力技术(如FlashAttention),降低了训练效率。针对这些问题,本文提出了原生可训练的稀疏注意力机制(Native Sparse Attention,NSA),旨在通过算法创新与硬件对齐优化,实现高效的长上下文建模,平衡模型性能与计算效率。
二、NSA核心工作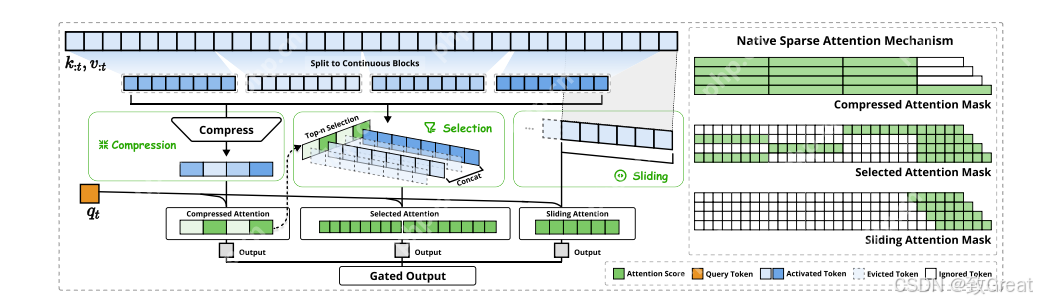
NSA的技术方法涵盖算法设计与内核优化。其整体框架基于对注意力机制的重新定义,通过设计不同的映射策略构建更紧凑、信息更密集的键值对表示,以减少计算量。同时,针对硬件特性进行内核优化,提升实际运行效率。
背景知识 注意力机制:在语言建模中,注意力机制广泛应用。对于输入序列长度为的情况,注意力操作定义为:
其中
表示注意力函数:
这里
是
与
之间的注意力权重,
是键的特征维度。随着序列长度增加,注意力计算在总计算成本中占比越来越大,给长上下文处理带来挑战。
算术强度:算术强度是计算操作与内存访问的比率,对硬件上的算法优化有重要影响。每个GPU都有由峰值计算能力和内存带宽决定的临界算术强度。对于计算任务,算术强度高于此临界阈值时受GPU浮点运算能力(FLOPS)限制,低于此阈值时受内存带宽限制。在因果自注意力机制中,训练和预填充阶段,批矩阵乘法和注意力计算算术强度高,属于计算受限阶段;而自回归解码时,每次前向传递仅生成一个令牌,但需加载整个键值缓存,算术强度低,受内存带宽限制。这导致不同阶段的优化目标不同:训练和预填充阶段需降低计算成本,解码阶段需减少内存访问。整体框架:为利用注意力的自然稀疏模式,NSA提出用更紧凑的键值对、
替代原始键值对
、
。优化后的注意力输出定义为:
其中
、
根据当前查询
和上下文内存
、
动态构建。通过设计多种映射策略可得到不同类别的
、
,并将它们组合起来:
NSA有三种映射策略
,分别代表压缩、选择和滑动窗口策略,用于处理键值对。
是对应策略
的门控分数,由输入特征经MLP和sigmoid激活得到。令
表示重新映射后的键/值总数:
通过确保
,NSA保持较高的稀疏率。
算法设计 令牌压缩(Token Compression):通过聚合连续的键或值块为块级表示,得到压缩后的键值对,以捕获整个块的信息。压缩键表示定义为:其中
是块长度,
是相邻块之间的滑动步长,
是带有块内位置编码的可学习MLP,用于将块中的键映射为单个压缩键。
是由压缩键组成的张量。通常采用
来减少信息碎片化。类似地,可定义压缩值表示
。压缩表示捕获更粗粒度的高级语义信息,降低注意力计算负担。
令牌选择(Token Selection):仅使用压缩键值对可能会丢失重要的细粒度信息,因此NSA设计了高效的令牌选择机制。 块级选择(Blockwise Selection):基于硬件效率和注意力分数的固有分布模式,NSA的选择策略按空间连续块处理键值序列。现代GPU架构对连续块访问具有更高的吞吐量,且块级计算能更好地利用张量核心。此外,注意力分数通常具有空间连续性,相邻键往往具有相似的重要性水平。重要性分数计算(Importance Score Computation):计算块重要性分数可能会带来较大开销。NSA利用压缩令牌的注意力计算产生的中间注意力分数来推导选择块的重要性分数。公式为:其中
是
与压缩键
之间的注意力分数。当压缩块和选择块具有相同的分块方案(即
)时,可直接得到选择块重要性分数
。对于分块方案不同的情况(假设
且
),通过下式推导选择块的重要性分数:
在采用GQA或MQA的模型中,为最小化解码时的KV缓存加载,需确保跨查询头的一致块选择。同一组内跨头的共享重要性分数定义为:
其中
表示头索引,
是每组中的查询头数量。
Top - n块选择(Top - n Block Selection):获得选择块重要性分数后,保留按块重要性分数排名前的稀疏块中的令牌。公式为:
其中
表示降序排名位置,
对应最高分数,
是所选块的索引集,
表示拼接操作。
是由选择的键组成的张量。类似地,可定义细粒度值
。这些选择的键值对参与与
的注意力计算。
滑动窗口(Sliding Window):在注意力机制中,局部模式可能会主导学习过程,影响模型从压缩和选择令牌中学习。为解决此问题,NSA引入滑动窗口分支专门处理局部上下文。具体而言,NSA维护一个窗口内的近期令牌
,
,并将不同信息源(压缩令牌、选择令牌、滑动窗口)的注意力计算分离到不同分支。这些分支输出通过学习的门控机制聚合。为防止注意力分支间的梯度干扰,NSA为三个分支提供独立的键值对。这种架构设计在引入最小开销的同时,通过防止局部和长距离模式识别之间的梯度干扰,实现稳定学习。
最终输出计算:获得压缩、选择和滑动窗口这三类键值对(,
;
,
;
,
)后,按照公式
计算最终的注意力输出,这构成了NSA完整的算法框架。
内核设计:为在训练和预填充阶段实现类似FlashAttention的加速效果,NSA基于Triton实现了硬件对齐的稀疏注意力内核。当前先进的大语言模型多采用共享KV缓存的架构(如GQA和MQA),NSA聚焦于此。压缩和滑动窗口注意力计算可与现有FlashAttention - 2内核兼容,而对于稀疏选择注意力,NSA提出了专门的内核设计。若采用FlashAttention将时间连续的查询块加载到SRAM的策略,由于块内查询可能需要不连续的KV块,会导致内存访问效率低下。NSA的关键优化在于采用不同的查询分组策略:对于查询序列上的每个位置,将GQA组内的所有查询头(它们共享相同的稀疏KV块)加载到SRAM。其内核设计具有以下关键特征: 以组为中心的数据加载(Group - Centric Data Loading):对于每个内循环,加载组内位置处所有头的查询
及其共享的稀疏键/值块索引
。
共享KV获取(Shared KV Fetching):在内循环中,按顺序将连续的键/值块加载到SRAM中,分别表示为
,
,以最小化内存加载,其中
是满足
的内核块大小。
网格外循环(Outer Loop on Grid):由于不同查询块的内循环长度(与所选块数成比例)几乎相同,NSA将查询/输出循环放入Triton的网格调度器中,简化并优化内核。
优势:这种设计通过组间共享消除冗余的KV传输,并平衡GPU流式多处理器的计算负载,实现接近最优的算术强度。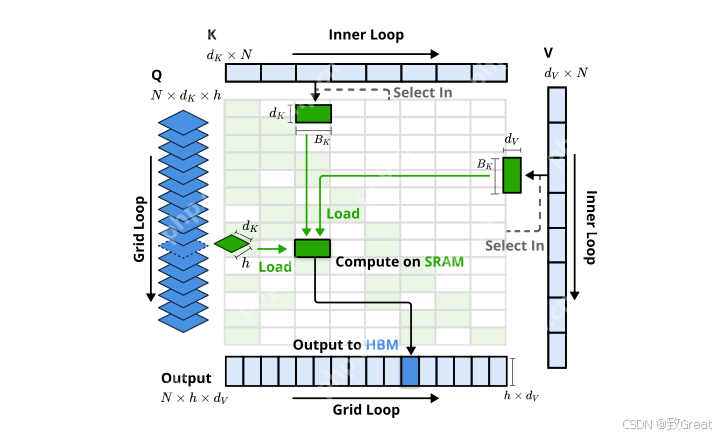
,
。对于MoE,采用DeepSeekMoE结构,有72个路由专家和2个共享专家,设置前
个专家为6。为确保训练稳定性,第一层的MoE替换为SwiGLU形式的MLP。对于NSA,设置压缩块大小
,滑动步长
,选择块大小
,选择块数量
(包括固定激活的1个初始块和2个局部块),滑动窗口大小
。全注意力模型和稀疏注意力模型均在2700亿个8k长度文本令牌上预训练,然后使用YaRN在32k长度文本上继续训练和监督微调,以实现长上下文适应。两个模型均训练至完全收敛,以确保公平比较。从预训练损失曲线来看,NSA和全注意力基线模型均呈现稳定平滑的下降趋势,且NSA始终优于全注意力模型。
基线方法:除与全注意力模型比较外,还评估了几种推理阶段的稀疏注意力方法,包括H2O、infLLM、Quest和Exact - Top。这些方法涵盖了不同的稀疏注意力范式,如KV缓存逐出、查询感知选择和精确的前稀疏选择。在一般评估中,由于大多数样本长度在稀疏注意力基线方法的局部上下文窗口内,这些方法实际上与全注意力等效,因此仅展示NSA与全注意力基线的比较结果。在长上下文评估中,对所有基线方法进行比较,并将所有稀疏注意力方法的稀疏度设置为相同,以确保公平性。在思维链推理评估中,由于稀疏注意力基线方法不支持训练,仅与全注意力模型进行比较。
性能比较 一般评估:在涵盖知识、推理和编码能力的综合基准测试中评估预训练的NSA和全注意力基线模型,包括MMLU、MMLU - PRO、CMMLU、BBH、GSM8K、MATH、DROP、MBPP和HumanEval等。结果显示,尽管NSA具有稀疏性,但在整体性能上表现优异,在9个指标中的7个上超过包括全注意力在内的所有基线模型。在推理相关基准测试(如DROP、GSM8K)中,NSA有显著提升,这表明其预训练有助于模型开发专门的注意力机制,通过过滤掉无关注意力路径的噪声,聚焦重要信息,从而提升性能。NSA在不同评估中的一致表现也验证了其作为通用架构的稳健性。长上下文评估:在64k上下文的“大海捞针”(Needle - in - a - haystack)测试中,NSA在所有位置均实现了完美的检索准确率。这得益于其分层稀疏注意力设计,压缩令牌用于高效的全局上下文扫描,选择令牌用于精确的局部信息检索。粗粒度压缩以低计算成本识别相关上下文块,而对选择令牌的令牌级注意力确保了关键细粒度信息的保留,使NSA能够同时保持全局感知和局部精度, 在LongBench基准测试中,NSA同样表现出色。为保证公平比较,将所有稀疏注意力基线模型中每个查询激活的令牌数设为2560,这与NSA处理32k序列长度时激活的平均令牌数一致。NSA在LongBench上取得了0.469的最高平均得分,超越了所有基线模型,比全注意力模型高出0.032,比Exact-Top高出0.046。这一优势源于NSA原生稀疏注意力设计,使稀疏模式在预训练阶段得以端到端优化,促进了稀疏注意力模块与模型其他组件的同步适配;同时,分层稀疏注意力机制实现了局部和全局信息处理的平衡。在需要长上下文复杂推理的任务中,NSA表现卓越,在多跳问答任务(HPQ和2Wiki)上比全注意力模型分别提升0.087和0.051,在代码理解(LCC)任务上提升0.069,在段落检索(PassR-en)任务上提升0.075,充分验证了其处理多样长上下文挑战的能力,以及原生预训练稀疏注意力在学习任务最优模式方面的优势。思维链推理评估:为评估NSA与先进下游训练范式的兼容性,研究通过知识蒸馏从DeepSeek-R1获取思维链数学推理能力,对NSA和全注意力模型进行监督微调(SFT)。使用100亿个32k长度的数学推理轨迹对模型进行微调,得到Full Attention-R和NSA-R两个模型,并在具有挑战性的美国数学邀请赛(AIME 24)基准上进行评估。在不同生成上下文限制(8k和16k令牌)下进行实验,以验证推理深度对准确性的影响。结果表明,在8k上下文设置下,NSA-R的准确率比Full Attention-R显著提高0.075,在16k上下文下优势依然存在,提高了0.054。这验证了原生稀疏注意力的两个关键优势:一是预训练的稀疏注意力模式能够有效捕捉复杂数学推导中至关重要的长距离逻辑依赖;二是NSA的硬件对齐设计保持了足够的上下文密度,支持随着推理深度增加而不会出现灾难性遗忘。在不同上下文长度下NSA-R的持续优异表现,证实了稀疏注意力在原生集成到训练管道中时,对先进推理任务的可行性。效率分析:在8-GPU A100系统上评估NSA相对于全注意力的计算效率,模型配置与实验部分一致。 训练速度:将基于Triton的NSA注意力实现与全注意力以及Triton-based FlashAttention-2进行比较。随着上下文长度增加,NSA的加速比逐渐增大,在64k上下文长度时,前向传播速度提升可达9.0倍,反向传播速度提升可达6.0倍。这种加速得益于NSA硬件对齐的算法设计:块级内存访问模式通过合并加载最大化了张量核心的利用率;内核中精细的循环调度消除了冗余的KV传输。解码速度:注意力的解码速度主要受内存访问瓶颈限制,与KV缓存加载量密切相关。在每个解码步骤中,NSA只需加载最多个压缩令牌、
个选择令牌和
个相邻令牌(
为缓存序列长度)。随着解码长度增加,NSA的延迟显著降低,在64k上下文长度时,速度提升可达11.6倍。且这种内存访问效率优势随着序列长度增加而更加明显。

回顾现有通过稀疏注意力提高注意力计算效率的方法,可大致分为三类:
固定稀疏模式:如SlidingWindow,仅允许查询在固定窗口内计算注意力。StreamingLLM通过维护上下文的两个关键部分(注意力汇聚和局部上下文窗口)来处理长文本流。这些方法虽能有效降低内存和计算成本,但固定的上下文忽略模式限制了其在需要全上下文理解任务上的性能。动态令牌剪枝:H2O在解码过程中实现了自适应方法以减少KV缓存内存使用,根据注意力分数动态逐出对未来预测不太重要的令牌。SnapKV引入令牌剪枝策略,通过注意力权重分析和投票在预填充阶段识别重要特征,然后更新KV缓存,结合所选压缩特征和近期上下文以保持提示一致性,从而有效利用内存。查询感知选择:Quest采用块级选择策略,通过查询与键块的坐标最小 - 最大乘积估计每个块的重要性,选择前个重要的键值块进行注意力计算。InfLLM结合固定模式与检索,通过维护注意力汇聚、局部上下文和可检索块,从每个块中选择代表性键来估计块重要性。HashAttention将关键令牌识别问题转化为推荐问题,通过学习函数将查询和键映射到汉明空间。ClusterKV通过首先对键进行聚类,然后根据查询 - 聚类相似性选择最相关的聚类进行注意力计算来实现稀疏性。
(五)结论本文提出的NSA是一种硬件对齐的稀疏注意力架构,用于高效的长上下文建模。通过在可训练架构中集成分层令牌压缩和块级令牌选择,NSA在保持全注意力性能的同时,实现了训练和推理的加速。实验结果表明,NSA在一般基准测试中的性能与全注意力基线相当,在长上下文评估中超越了其他模型的建模能力,在推理能力上也有显著提升,同时显著降低了计算延迟,实现了可观的速度提升。NSA推动了稀疏注意力技术的发展,为大语言模型在长上下文处理方面提供了更高效的解决方案。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>










热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 2023修仙外传手游排行榜-修仙外传手游2023排行榜前十名下载
- 三国消雄排行榜下载大全-2023最好玩的三国消雄前十名推荐
- 九百打金排行榜下载大全-2023最好玩的九百打金前十名推荐
- 2023夺宝英雄手游排行榜-夺宝英雄手游2023排行榜前十名下载
- 2023战国争霸手游排行榜-战国争霸手游2023排行榜前十名下载
- 像素求生排行榜下载大全-2023最好玩的像素求生前十名推荐
- 青云诀2排行榜下载大全-2023最好玩的青云诀2前十名推荐
- 类似传奇国度的游戏排行榜_有哪些类似传奇国度的游戏
- 传奇私服排行榜下载大全-2023最好玩的传奇私服前十名推荐
- 攻沙传奇排行榜下载大全-2023最好玩的攻沙传奇前十名推荐
- 类似猩月屠龙的手游排行榜下载-有哪些好玩的类似猩月屠龙的手机游戏排行榜
- 2023青鸟传说手游排行榜-青鸟传说手游2023排行榜前十名下载
热门攻略
更多>>





手机扫描此二维码,
在手机上查看此页面
版权投诉请发邮件到 cn486com#outlook.com (把#改成@),我们会尽快处理
Copyright © 2019-2020 菜鸟下载(www.cn486.com).All Reserved | 备案号:湘ICP备2022003375号-1
本站资源均收集整理于互联网,其著作权归原作者所有,如有侵犯你的版权,请来信告知,我们将及时下架删除相应资源