图解 DeepSeek-R1
作者 | jay alammar译者 | 王强策划 | Tina图片DeepSeek-R1 是人工智能持续发展中的一个
作者 | jay alammar
译者 | 王强
策划 | Tina
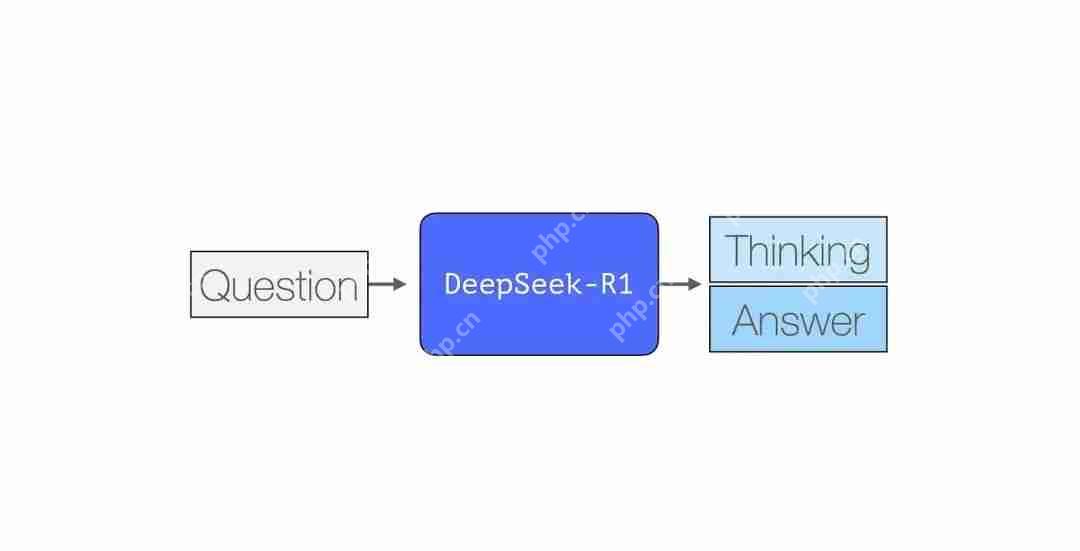 图片DeepSeek-R1 是人工智能持续发展中的一个重要里程碑。对于机器学习研发社区而言,这是一个关键版本,原因包括:
图片DeepSeek-R1 是人工智能持续发展中的一个重要里程碑。对于机器学习研发社区而言,这是一个关键版本,原因包括:
它是一个开放权重模型,包含一些较小的、简化的版本,并且它分享并应用了一种训练方法,以重现类似于 OpenAI O1 的推理模型。在本文中,我们将探索它的构建方式。
内容:
回顾:如何训练大型语言模型(LLM)DeepSeek-R1 的训练配方1- 长链推理监督微调(SFT)数据2- 暂用高质量推理 LLM(但在非推理任务中表现不佳)3- 使用大规模强化学习(RL)创建推理模型3.1- 大规模推理导向强化学习(R1-Zero)3.2- 使用暂用推理模型生成 SFT 推理数据3.3- 一般 RL 训练阶段架构了解此类模型如何运作所需的大部分基础知识可以在我们的电子书《动手实践大型语言模型(https://www.php.cn/link/065f16a07047ae1c3b0c4ab8da87fe8e)》中找到。
1回顾:LLM 的训练方式
与大多数现有的 LLM 一样,DeepSeek-R1 一次生成一个 token,但它在解决数学和推理问题方面表现得更好,因为它能够通过生成解释其思维链的思考 token 来花费更多时间处理问题。
 图片下图来自我们书中的第 12 章,展示了通过三个步骤创建高质量 LLM 的通用方法:
图片下图来自我们书中的第 12 章,展示了通过三个步骤创建高质量 LLM 的通用方法:
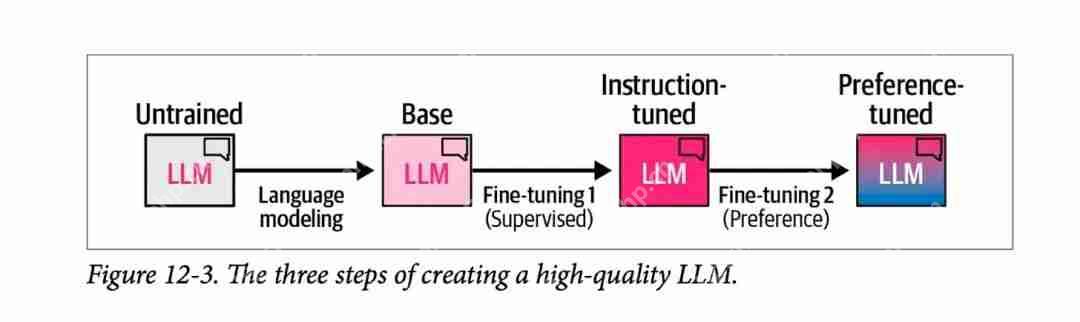 图片1) 语言建模步骤,我们使用大量网络数据训练模型,以使其预测下一个单词。这一步骤会生成一个基础模型。
图片1) 语言建模步骤,我们使用大量网络数据训练模型,以使其预测下一个单词。这一步骤会生成一个基础模型。
2) 监督微调步骤,使模型更好地遵循指令和回答问题。此步骤生成一个指令调整模型或监督微调 /SFT 模型。
3) 最后是偏好微调步骤,进一步完善其行为并使其符合人类偏好,从而生成最终的偏好微调 LLM,你可以在演示 Playground 和应用上与之交互。
2DeepSeek-R1 训练配方
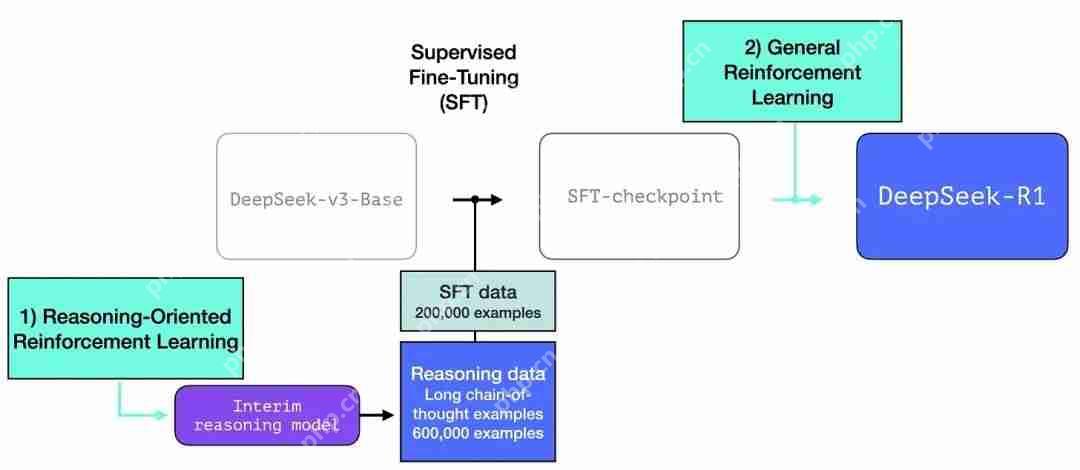
DeepSeek-R1 遵循这个通用配方。第一步的细节来自于前一篇关于 DeepSeek-V3 模型的论文(https://www.php.cn/link/286b0b3ea509af1aeff6bb47299d96d7)。R1 使用的是前一篇论文中的基础模型(而不是最终生成的 DeepSeek-v3 模型),并且也经过了 SFT 和偏好微调步骤,但执行步骤的具体细节有所不同。
 图片在 R1 创建过程中,有三个特别之处需要强调。
图片在 R1 创建过程中,有三个特别之处需要强调。
3长链推理 SFT 数据
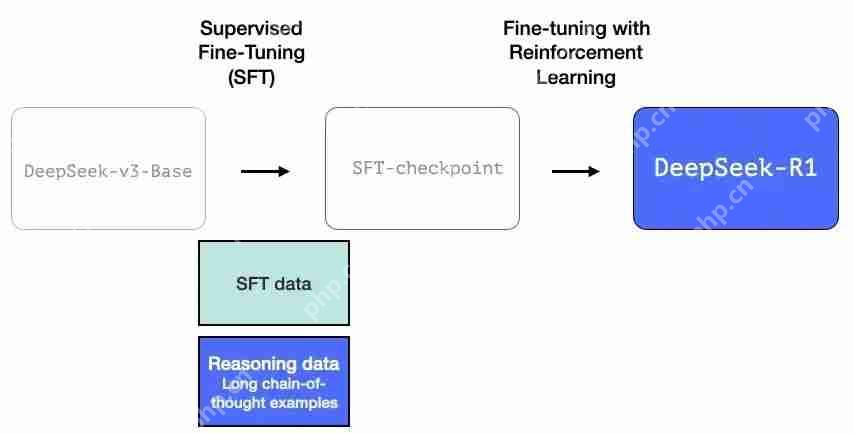 图片上图是一个大样本长链思维推理示例(600,000 个)。这些示例很难获得,而且在这种规模下用人工标记的成本非常高。这就是为什么创建它们的过程是第二个需要强调的特殊之处。
图片上图是一个大样本长链思维推理示例(600,000 个)。这些示例很难获得,而且在这种规模下用人工标记的成本非常高。这就是为什么创建它们的过程是第二个需要强调的特殊之处。
4一个暂用的高质量推理 LLM(但在非推理任务方面表现较差)。
这些数据是由 R1 的一个前身创建的,R1 的前身是一个未命名的兄弟版本,专门设计用于推理任务。这个兄弟模型的灵感来自第三个模型 R1-Zero(我们将很快讨论它)。它之所以很重要,并不是因为它是一个很棒的 LLM,而是因为创建它只需要很少的标记数据以及大规模强化学习即可,这样就做出来了一个擅长解决推理问题的模型。
然后就可以使用这个未命名的专业推理模型的输出,来训练一个更通用的模型,新的模型也可以执行其他非推理任务,并达到用户对 LLM 的期望水平。
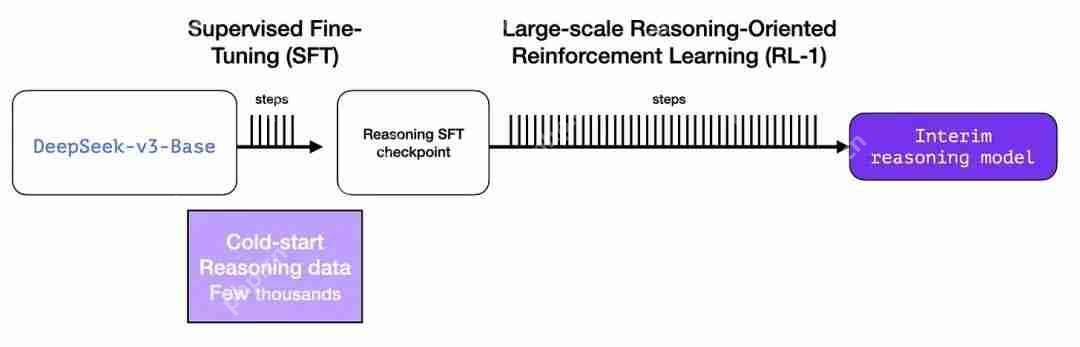
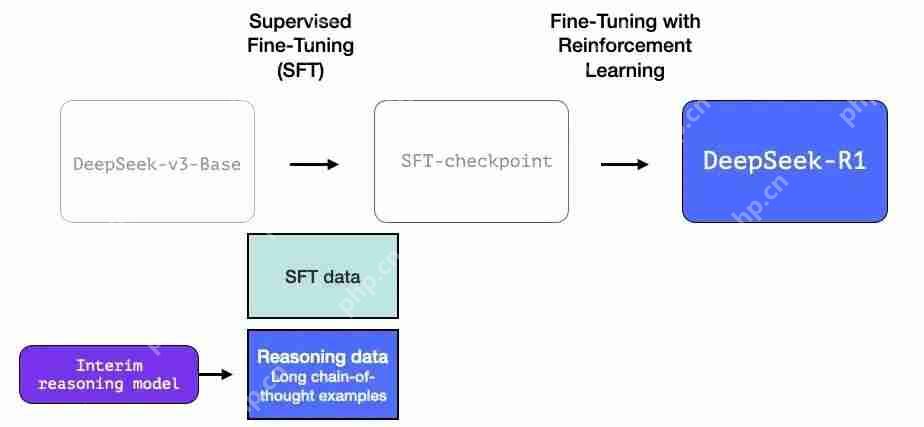 图片5使用大规模强化学习(RL)创建推理模型
图片5使用大规模强化学习(RL)创建推理模型
这分为两个步骤:
 图片 3.1 大规模推理导向强化学习(R1-Zero)
图片 3.1 大规模推理导向强化学习(R1-Zero)
在这里,RL 用于创建一个暂用推理模型。然后使用该模型生成 SFT 推理示例。为了创建这个模型还在早期做了一个实验,该实验创建了一个名为 DeepSeek-R1-Zero 的早期模型。
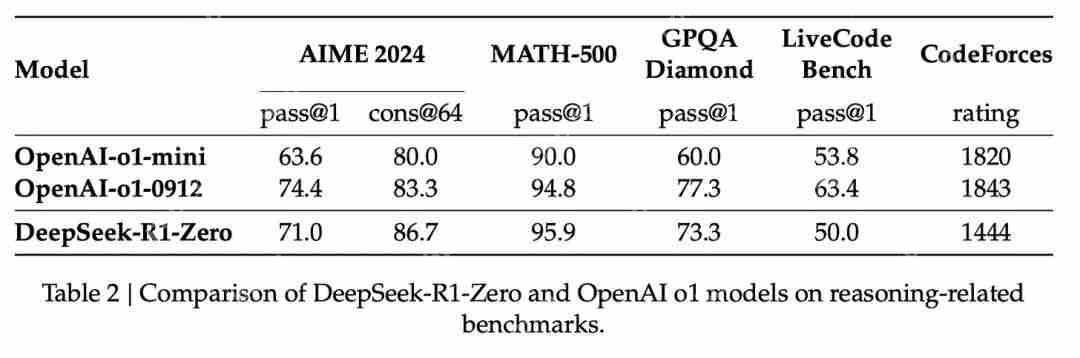 图片R1-Zero 之所以特殊,是因为它能够在没有使用标记的 SFT 训练集的情况下出色地完成推理任务。它的训练直接从一个预训练的基础模型开始,经过 RL 训练过程(没有 SFT 步骤)。它做得非常好,以至于可以与 o1 相提并论。
图片R1-Zero 之所以特殊,是因为它能够在没有使用标记的 SFT 训练集的情况下出色地完成推理任务。它的训练直接从一个预训练的基础模型开始,经过 RL 训练过程(没有 SFT 步骤)。它做得非常好,以至于可以与 o1 相提并论。
 图片这样的做法非常亮眼,因为数据一直是 ML 模型能力的燃料。这个模型如何摆脱这一局限?这里有两点:
图片这样的做法非常亮眼,因为数据一直是 ML 模型能力的燃料。这个模型如何摆脱这一局限?这里有两点:
现代基础模型已经跨越了一定的质量和能力门槛(这个基础模型是在 14.8 万亿个高质量 token 上训练的)。与一般的聊天或写作请求相比,推理问题可以自动验证或标记。我们用一个例子来展示这一点。示例:推理问题的自动验证
下面可以是作为这个 RL 训练步骤一部分的一个提示 / 问题:
像这样的问题可以通过多种方式进行自动验证。假设我们将这个问题提交给正在训练的模型,它会生成一个代码补全:
软件 linter 可以检查补全是否是正确的 Python 代码我们可以执行 Python 代码来查看它是否能正确运行其他现代编程 LLM 可以创建单元测试来验证所需的行为(无需自己成为推理专家)。我们甚至可以更进一步测量执行时间,并使训练过程优先选择性能更高的解决方案——即使其他解决方案也是可以正确解决问题的 Python 程序。我们可以在一个训练步骤中向模型提出这样的问题,并生成多个可能的解决方案。
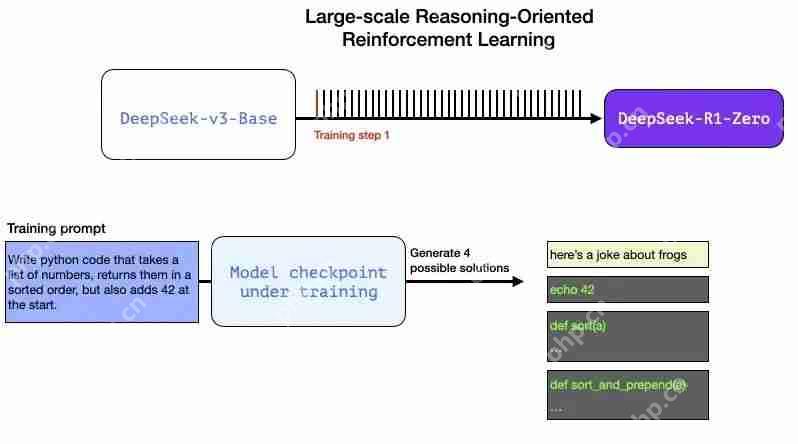 图片我们可以自动检查(无需人工干预)并发现第一个输出的补全甚至不是代码。第二个是代码,但不是 Python 代码。第三个是可能的解决方案,但未通过单元测试,第四个是正确的解决方案。
图片我们可以自动检查(无需人工干预)并发现第一个输出的补全甚至不是代码。第二个是代码,但不是 Python 代码。第三个是可能的解决方案,但未通过单元测试,第四个是正确的解决方案。
这些都是可以直接用于改进模型的信号。当然,这是通过许多示例(小批量)和连续的训练步骤完成的。
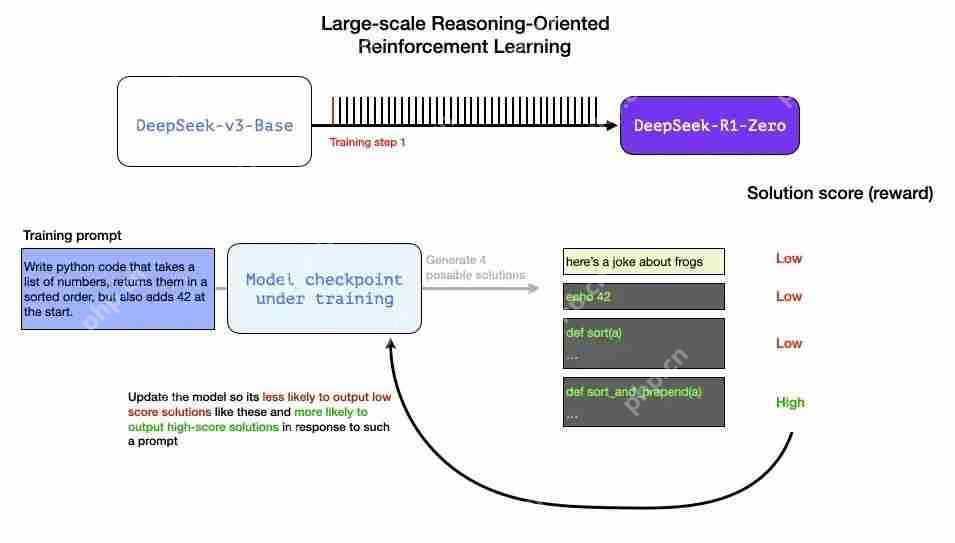 图片这些奖励信号和模型更新是模型在 RL 训练过程中持续改进任务的方式,如论文中的图 2 所示。
图片这些奖励信号和模型更新是模型在 RL 训练过程中持续改进任务的方式,如论文中的图 2 所示。
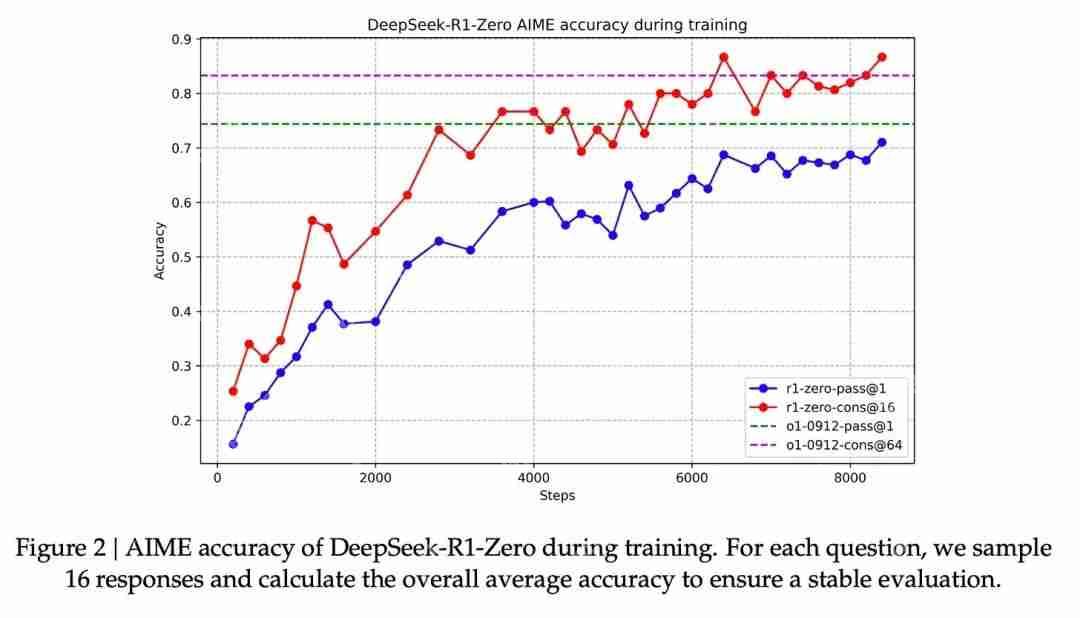 图片与这种能力改进相对应的是生成的响应的长度,其中模型会生成更多的思考 token 来处理问题。
图片与这种能力改进相对应的是生成的响应的长度,其中模型会生成更多的思考 token 来处理问题。
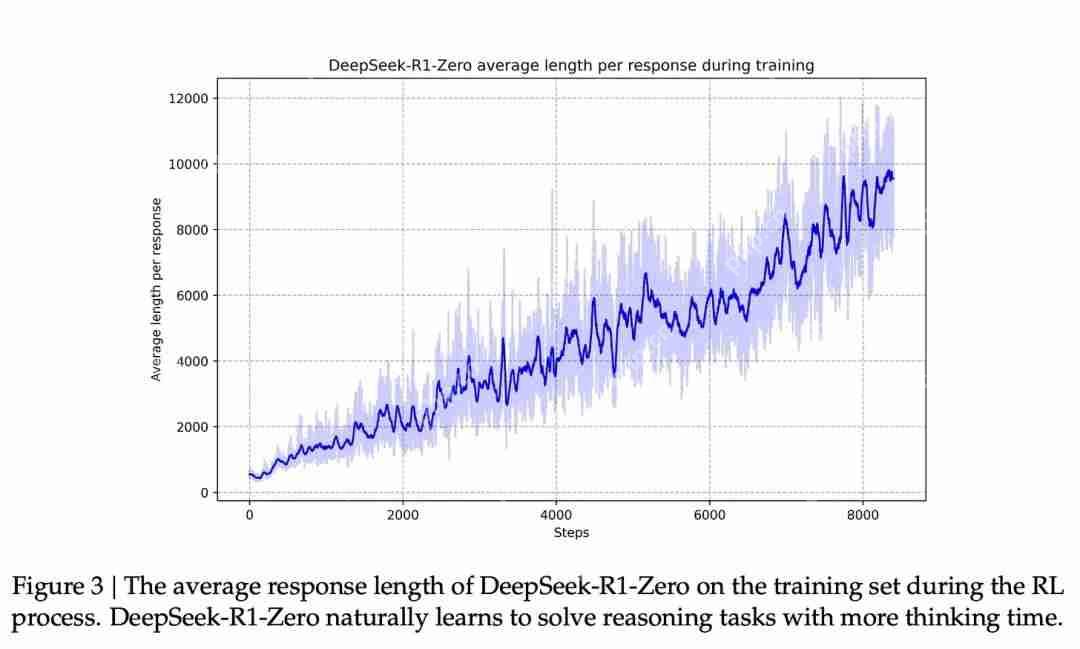 图片这个过程很有用,但尽管 R1-Zero 模型在这些推理问题上得分很高,它也存在其他一些问题,使其可用性不及预期。
图片这个过程很有用,但尽管 R1-Zero 模型在这些推理问题上得分很高,它也存在其他一些问题,使其可用性不及预期。
R1 的设计目标是成为一个更可用的模型。因此,我们不必完全依赖 RL 过程,只需在本节前面提到的两个地方使用它即可:
创建一个暂用推理模型以生成 SFT 数据点训练 R1 模型以改进推理和非推理问题(使用其他类型的验证器)图片 3.2 使用暂用推理模型创建 SFT 推理数据
为了使暂用推理模型更有用,它会基于几千个推理问题示例(其中一些是从 R1-Zero 生成和过滤的)进行监督微调(SFT)训练步骤。本文将其称为“冷启动数据”
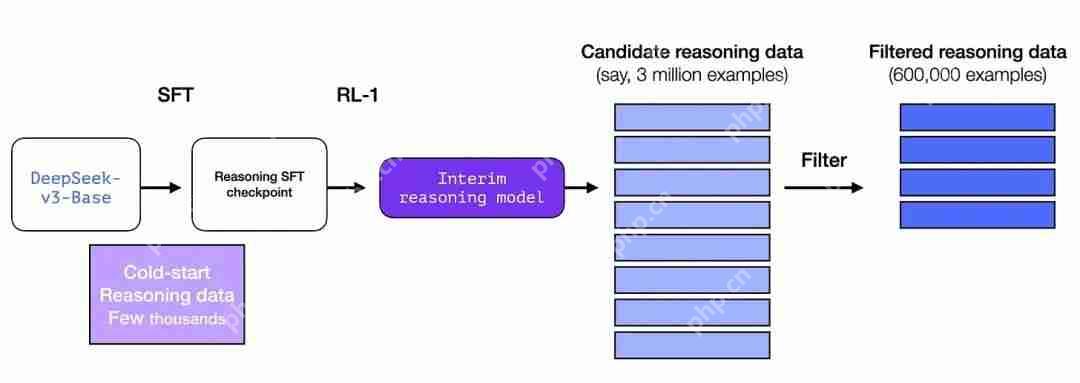
 图片但如果我们已经有了这些数据,那为什么还要依赖 RL 过程呢?这是因为数据的规模。这个数据集可能有 5,000 个示例(差不多),但要训练 R1 需要 600,000 个示例。这个暂用模型弥补了这一差距,并能合成生成极有价值的数据。
图片但如果我们已经有了这些数据,那为什么还要依赖 RL 过程呢?这是因为数据的规模。这个数据集可能有 5,000 个示例(差不多),但要训练 R1 需要 600,000 个示例。这个暂用模型弥补了这一差距,并能合成生成极有价值的数据。
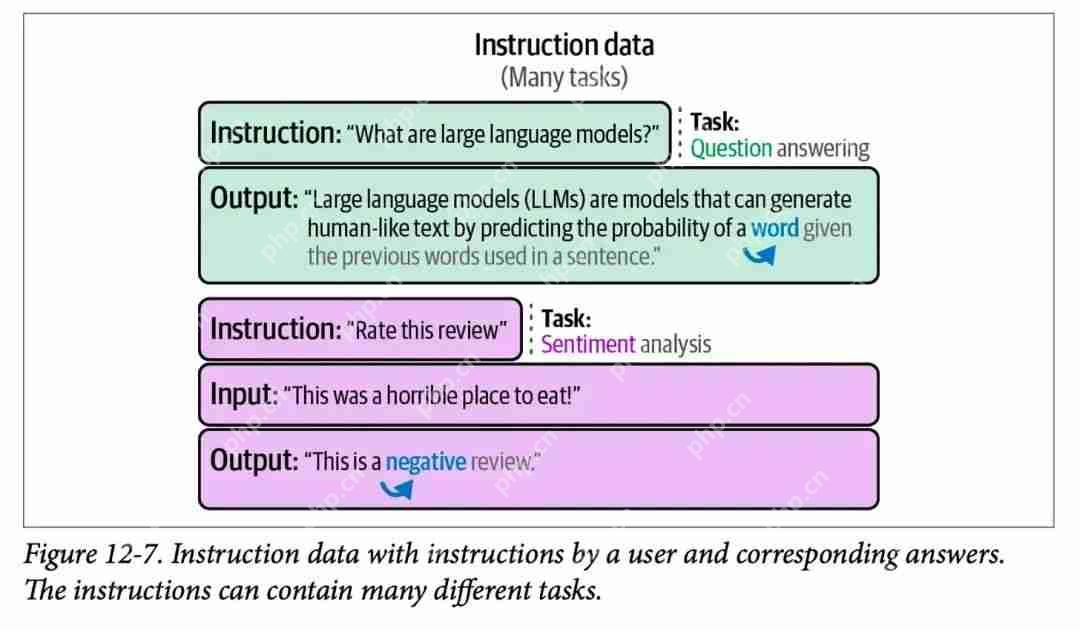
 图片如果你不熟悉监督微调(SFT)的概念,这里提一下它是以提示和正确补全的形式向模型提供训练示例的过程。第 12 章中的这张图展示了几个 SFT 训练示例:
图片如果你不熟悉监督微调(SFT)的概念,这里提一下它是以提示和正确补全的形式向模型提供训练示例的过程。第 12 章中的这张图展示了几个 SFT 训练示例:
 图片 3.3 通用 RL 训练阶段
图片 3.3 通用 RL 训练阶段
这一步让 R1 能够擅长推理以及其他非推理任务。该过程类似于我们之前看到的 RL 过程。但由于它扩展到了非推理应用程序上,因此它利用了有用性和安全奖励模型(与 Llama 模型不同)来处理属于这些应用程序的提示。
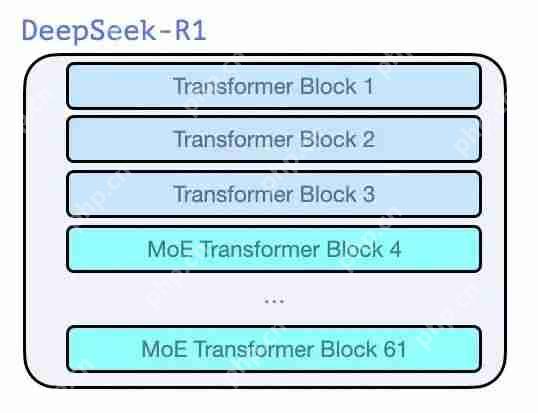
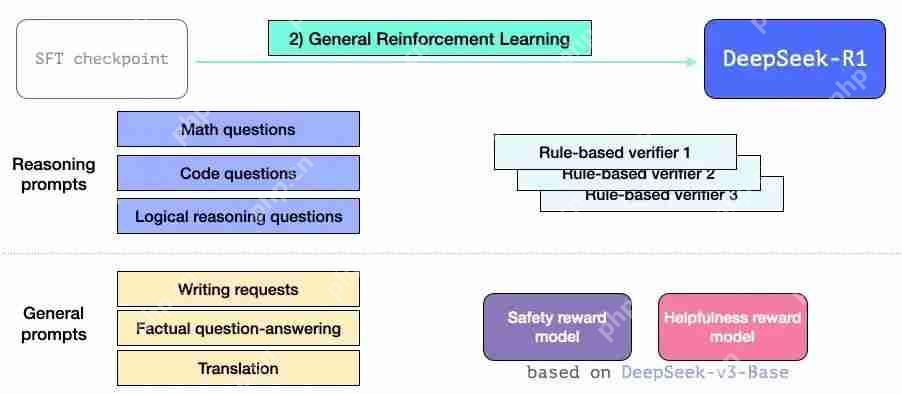 图片6架构
图片6架构
就像 GPT2 和 GPT 3 诞生之初时的那些模型一样,DeepSeek-R1 是 Transformer 解码器块的堆栈。它由 61 个 Transformer 解码器块组成。前三个是密集的,但其余的是混合专家层(请参阅我的合著者 Maarten 的精彩入门指南:混合专家(MoE)的可视化指南,https://www.php.cn/link/60ee22c27013613e980104db94ae53c9)。
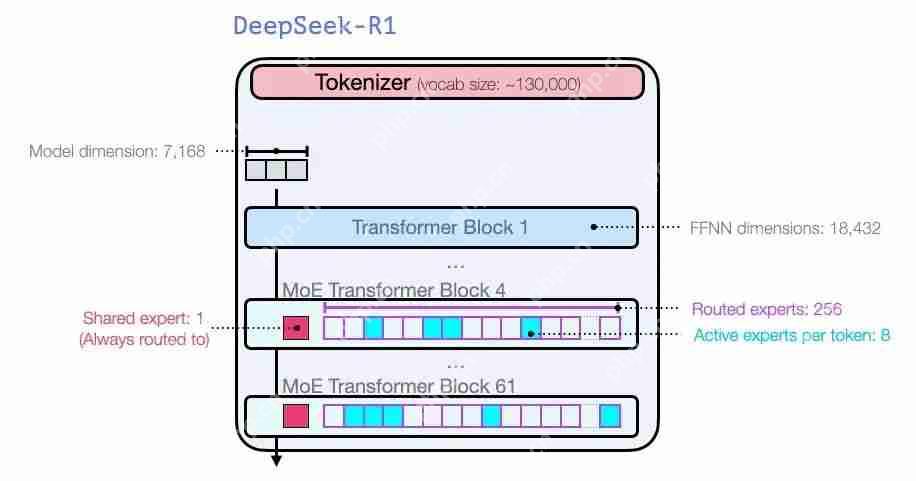
 图片就模型维度大小和其他超参数而言,它们是这个样子:
图片就模型维度大小和其他超参数而言,它们是这个样子:
 图片有关模型架构的更多细节,请参阅他们之前的两篇论文:
图片有关模型架构的更多细节,请参阅他们之前的两篇论文:
DeepSeek-V3 技术报告(https://www.php.cn/link/286b0b3ea509af1aeff6bb47299d96d7)DeepSeekMoE:混合专家语言模型迈向终极专业化*(https://arxiv.org/pdf/2401.06066)*7总结
这篇文章应该能让你对 DeepSeek-R1 模型有了基本的认知。
 图片如果你觉得自己需要更多基础信息来理解这篇文章,我建议你拿起一本《动手操作大型语言模型》或在 Github 上查看(https://www.php.cn/link/065f16a07047ae1c3b0c4ab8da87fe8e)。
图片如果你觉得自己需要更多基础信息来理解这篇文章,我建议你拿起一本《动手操作大型语言模型》或在 Github 上查看(https://www.php.cn/link/065f16a07047ae1c3b0c4ab8da87fe8e)。
原文链接:
https://www.php.cn/link/1b4f877baadb44b36ff73a44e05ebd4c
声明:本文为 InfoQ 翻译,未经许可禁止转载。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。

相关文章
更多>>











热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 金刚之印最新排行榜-金刚之印手游免费版下载-金刚之印免费破解版下载
- 炽焰传奇最新排行榜-炽焰传奇手游免费版下载-炽焰传奇免费破解版下载
- 欧陆风云系列版本排行-欧陆风云系列游戏有哪些版本-欧陆风云系列游戏破解版
- 多种热门耐玩的忍者学园破解版游戏下载排行榜-忍者学园破解版下载大全
- 2023圣剑生存手游排行榜-圣剑生存手游2023排行榜前十名下载
- 百龙霸业手游2023排行榜前十名下载_好玩的百龙霸业手游大全
- 谋略天下游戏版本排行榜-谋略天下游戏合集-2023谋略天下游戏版本推荐
- 渡劫封神手游排行-渡劫封神免费版/单机版/破解版-渡劫封神版本大全
- 传奇续章排行榜下载大全-2023最好玩的传奇续章前十名推荐
- 放置少女系列版本排行-放置少女系列游戏有哪些版本-放置少女系列游戏破解版
- 森系少女排行榜下载大全-2023最好玩的森系少女前十名推荐
- 类似天堂奇缘的游戏排行榜_有哪些类似天堂奇缘的游戏
热门攻略
更多>>





手机扫描此二维码,
在手机上查看此页面
版权投诉请发邮件到 cn486com#outlook.com (把#改成@),我们会尽快处理
Copyright © 2019-2020 菜鸟下载(www.cn486.com).All Reserved | 备案号:湘ICP备2022003375号-1
本站资源均收集整理于互联网,其著作权归原作者所有,如有侵犯你的版权,请来信告知,我们将及时下架删除相应资源