对于企业私有大模型DeepSeek的部署,应该选择Ollama还是vLLM?
来源:菜鸟下载 | 更新时间:2025-04-24
前言对于对数据敏感的企业,如果想要部署自己的大模型(例如:DeepSeek R1),可以考虑使用Olla

前言
对于对数据敏感的企业,如果想要部署自己的大模型(例如:DeepSeek R1),可以考虑使用Ollama或vLLM这两种方式。总体结论是:
①. Ollama 更适合用于开发和测试阶段。
②. vLLM 则更加适合用于生产环境的部署。
接下来,我将进行详细的对比,以便让你对这两者有更清晰的理解。
选型对比
Ollama与vLLM都是针对大语言模型(LLM)部署和推理的开源框架,但它们在设计目标、技术特点和适用场景上有显著的差异。下面通过多个维度给出具体对比说明。
核心定位与部署方式
Ollama:主要面向本地轻量化部署,利用Docker容器技术简化模型的运行流程,使用户能够以较少的配置迅速启动模型,非常适合个人开发者或资源受限的环境。
vLLM:注重于高性能推理与服务器扩展,支持多机多卡的分布式部署,通过优化GPU资源利用率和内存管理技术(例如PagedAttention),在高并发场景中显著提升吞吐量。
技术特点
Ollama:
- 简化部署:将模型权重、配置和依赖打包为统一格式,通过简单命令(如ollama run)即可启动模型。
- 资源优化:专为单机环境优化GPU使用,适合实时响应需求,但在大规模并发支持上有所限制。
- 跨平台支持:与多种操作系统兼容,强调易用和灵活性。
vLLM:
- 高效内存管理:采用PagedAttention技术,能够动态分配内存,降低冗余,支持更大上下文长度。
- 连续批处理(Continuous Batching):通过动态调度算法合并请求,以最大化GPU的使用效率,从而显著提高吞吐量。
- 量化支持:集成GPTQ等量化技术,降低显存占用并加速推理。
适用场景
Ollama:
- 轻量级应用:适合在个人电脑、移动设备或单机环境中进行少量并发推理,如本地开发、原型验证或实时交互。
- 快速实验:便于研究者或爱好者快速切换和测试不同模型(例如Llama系列)。
vLLM:
- 高并发服务:特别适合需要处理大量请求的生产环境(如API服务、聊天机器人),并支持在流量高峰时进行分布式扩展。
- 资源密集型任务:在多GPU集群中表现优异,适合企业级应用或需要低延迟、高吞吐的场景。
性能对比
- 吞吐量:vLLM因采用连续批处理和内存优化,吞吐量显著高于Ollama,尤其在高并发环境下差距明显。
- 资源占用:Ollama在单机环境中资源占用较低,启动快速,而vLLM需要更多的初始配置,但能更高效地利用多卡资源。
- 延迟:Ollama在实时响应需求上延迟更低,而vLLM通过批处理优化能够在吞吐量与延迟之间达到平衡。
开源生态与社区
Ollama:以易用性为核心,社区提供了丰富的预置模型(如Llama、Falcon),使其生态更贴近普通用户。
vLLM:技术聚焦于推理优化,社区活跃于性能提升和企业级功能开发,更适合需要深入技术支持的用户。
菜鸟下载发布此文仅为传递信息,不代表菜鸟下载认同其观点或证实其描述。
展开

相关文章
更多>>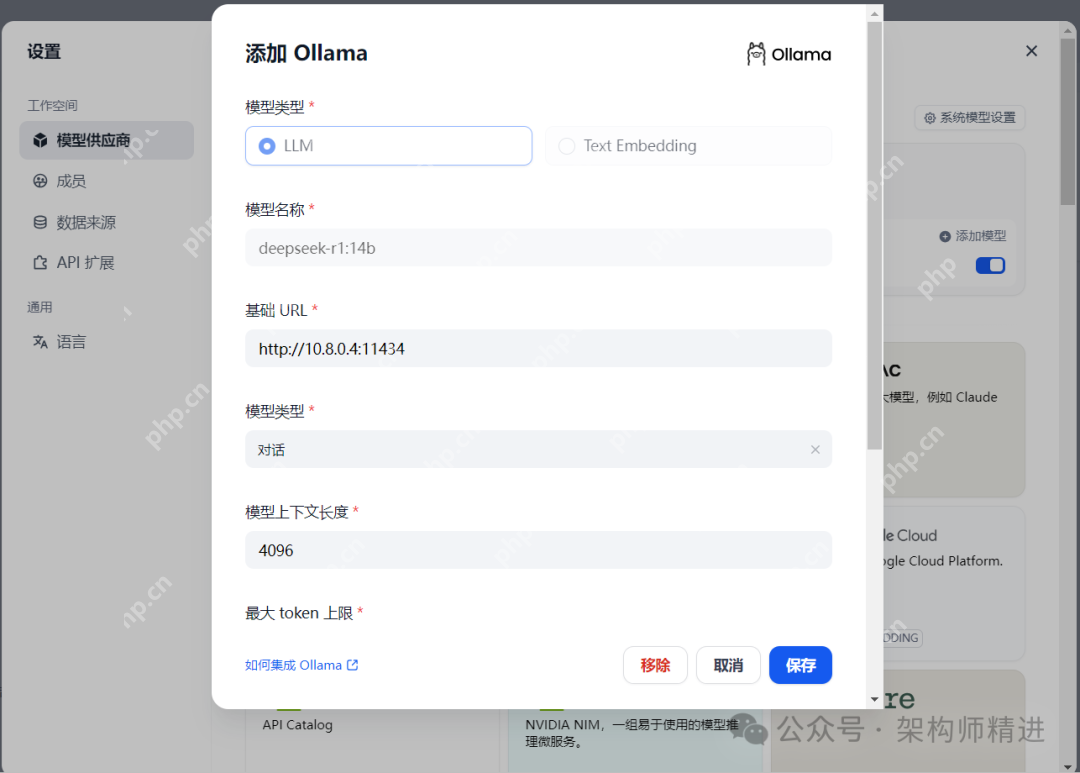




热门游戏
更多>>




热点资讯
更多>>热门排行
更多>>- 可靠快递游戏版本排行榜-可靠快递游戏合集-2023可靠快递游戏版本推荐
- 荒野行动手游排行榜-荒野行动手游下载-荒野行动游戏版本大全
- 2023侠义无双手游排行榜-侠义无双手游2023排行榜前十名下载
- 剑与江湖ios手游排行榜-剑与江湖手游大全-有什么类似剑与江湖的手游
- 类似龙渊之王的手游排行榜下载-有哪些好玩的类似龙渊之王的手机游戏排行榜
- 多种热门耐玩的悟空救我破解版游戏下载排行榜-悟空救我破解版下载大全
- 多种热门耐玩的挂机西游破解版游戏下载排行榜-挂机西游破解版下载大全
- 2023梦幻神途手游排行榜-梦幻神途手游2023排行榜前十名下载
- 侠录江湖手游2023排行榜前十名下载_好玩的侠录江湖手游大全
- 复古王者手游排行榜-复古王者手游下载-复古王者游戏版本大全
- 激战狂潮系列版本排行-激战狂潮系列游戏有哪些版本-激战狂潮系列游戏破解版
- 暗影之王手游2023排行榜前十名下载_好玩的暗影之王手游大全





